Hadas Kotek » Blog »
Text-to-image models are shallow in more ways than one (part 1)
Nov 6, 2023
For my seminar on Demystifying LLMs we’ve been thinking about what we can learn from Large Langauge Models (LLMs) about language and linguistics. So far the answer seems to be ‘not too much’, though I will hold onto my hope that there are interesting effects out there that could meaningfully inform our theories. On the other hand, it’s really not hard to find interesting effects with regard to ethics: hallucinations, bias, toxicity, misinformation, disinformation, etc., which teach us something deep and fundamental about the datasets the models are trained on, which I think is still very interesting to linguists, but for different reasons.
We recently explored multi-modal text-to-image models in class,1 specifically DALL·E 2 and Stable Diffusion XL.2 I was initially interested in whether there would be anything interesting to learn about how these models process language (spoiler: not much, but I’ll say more below). It quickly became clear that it’s much more interesting to think about ethics considerations with respect to these models.
This post will be a two-parter: even though I was very disappointed with these models’ language parsing abilities, there is still a lot to say. The next post will focus more specifically on ethics considerations, though as we’ll see that they come up here, too. Meanwhile, buckle up, we’re going to talk about some Ling 101 stuff.
[UPDATE (Nov 17, 2023): here’s part 2!]
Language understanding in text-to-image models
I was thinking it’d be interesting to think about how the models would deal with things like lexical ambiguity, structural ambiguity, vagueness, gibberish. The short version: it seems to me that the model isn’t doing much beyond picking out the nouns and using their most common (stereotypical) interpretation. I didn’t see any suggestion of actual syntactic parsing at any level.
Attachment ambiguities (part 1)
Let’s start with some very simple ambiguous noun phrases. First here’s, a side-by-side of “red apples and oranges” vs “red oranges and apples”:3


I bet you wouldn’t be able to guess which one is which if didn’t tell you.
These are simple examples of syntactic “bracketing” ambiguities: on one interpretation, “red” modifies the complex noun phrase while on the other “red” modifies the first noun alone. For example:
- [red apples] and oranges
- red [apples and oranges]
For “red apples and oranges”, there is a more sensible parse (only the apples are red, (1)) and a less sensible one (both the apples and the oranges are red, (2)), and you’d expect to see the models generate the more sensible reading given the likely training data. On the other hand for “red oranges and apples”, on either bracketing, the oranges have got to be red, no way around it. Nonetheless, we don’t really see a difference in the generated images.
That led me to try “red apples and peppers” vs “red peppers and apples”, since both can be red (or green), so I wondered if there’d be a difference there, but not really. Again, I don’t think you’d be able to independently guess which image corresponds to which prompt:


In fact, even just asking for something as simple as “blue oranges” already demonstrates that the model can’t overcome the biases in its training data:


Attachment ambiguities (part 2)
The next batch of prompts consists of attachment ambiguities at the phrasal level. At this point, I no longer expect that the model will have training data that could bear on the desired image, at least not directly, so we might be able to learn more about its language processing abilities. Spoiler: there’s little evidence that any real syntactic parsing is taking place!
I tried one of the most commonly used examples in intro to linguistics textbooks and courses: “the woman saw the man with the binoculars”. As with the examples above, there are two parses here that arise from two different possible attachment sites for the phrase “with the binoculars”:
- The woman [saw [the man] [with the binoculars]]
- The woman [saw [the man with the binoculars]]
On reading (1), “with the binoculars” modifies the verb “saw”, leading to the interpretation that the woman (the subject of seeing) used the binoculars. On reading (2), “with the binoculars” modifies the noun “man”, so the man has the binoculars. Here is what the model does:
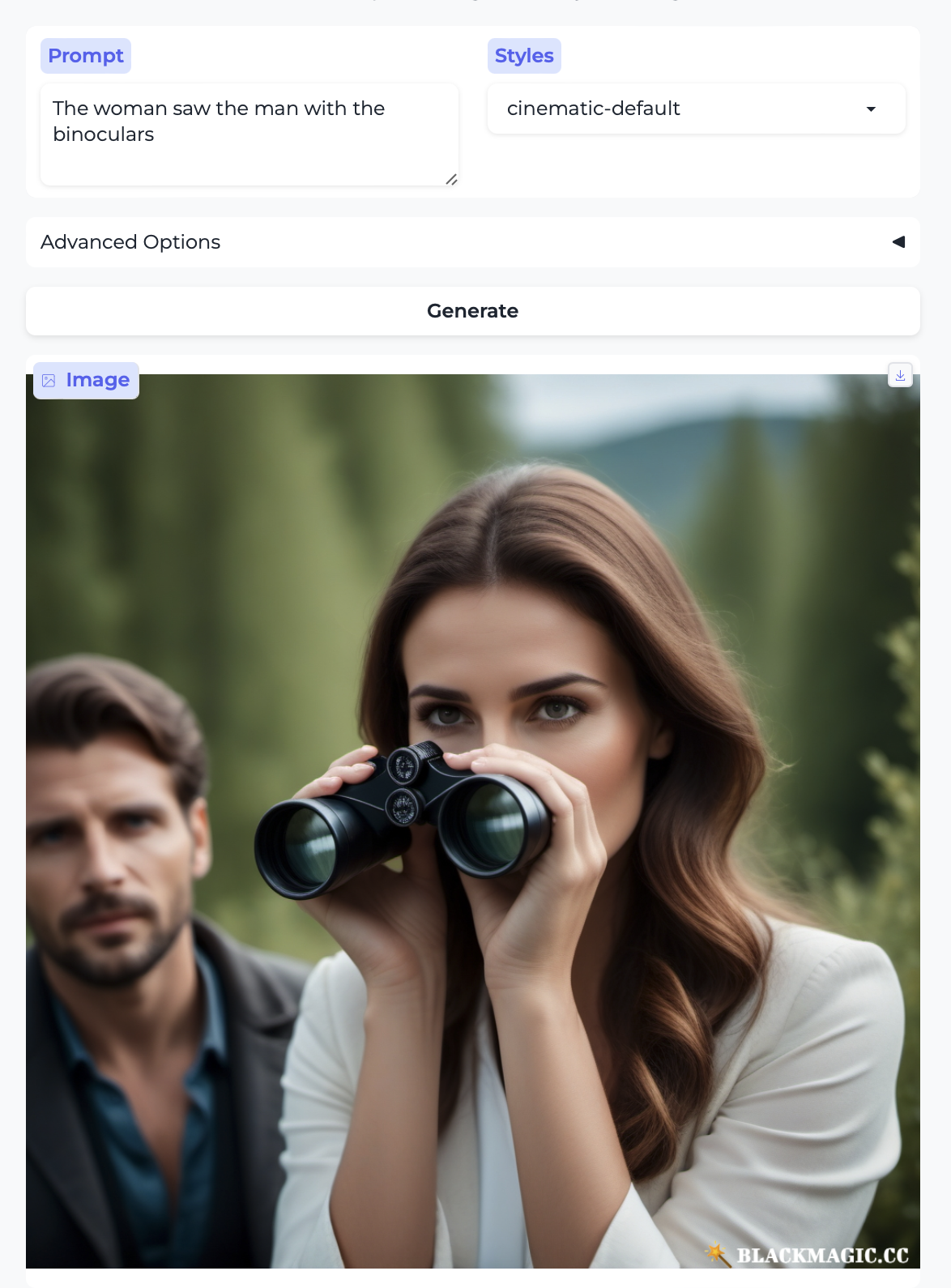

In both images, the woman is holding the binoculars, which might lead you to think it’s assigned the sentence structure (1). One of the images also has a man, but he’s behind the woman so it’s not clear how the woman would see him, binoculars or not. The other image features a woman with two right hands and no man, so you should be rightly suspicious of how much real parsing has happened here at all.
Just for fun I also tried “the man saw the woman with the binoculars”, and here’s what I got:

Now we get a three-handed woman holding binoculars and no man, so I think we can reasonably conclude that there’s really no deep parsing going on, and for some reason in these sentences the women always get to hold the binoculars. We never get two protagonists – a man and a woman – together in a setting such that the subject can see the object (with or without binoculars).
Lexical ambiguity
One common word linguists like to use to illustrate lexical ambiguities is “bank”, which can be used to mean either the edge of a river or lake or a financial institution. I tried Jane went to the bank and the model was like “Haha! I shall not even try”:

Anyway, if we were to successfully get the model to do something interesting, I imagine the most we’d be able to do is learn what is the most common sense of an ambiguous word in the training corpus. I didn’t spend any more time exploring this direction.
Nonsensical sentences
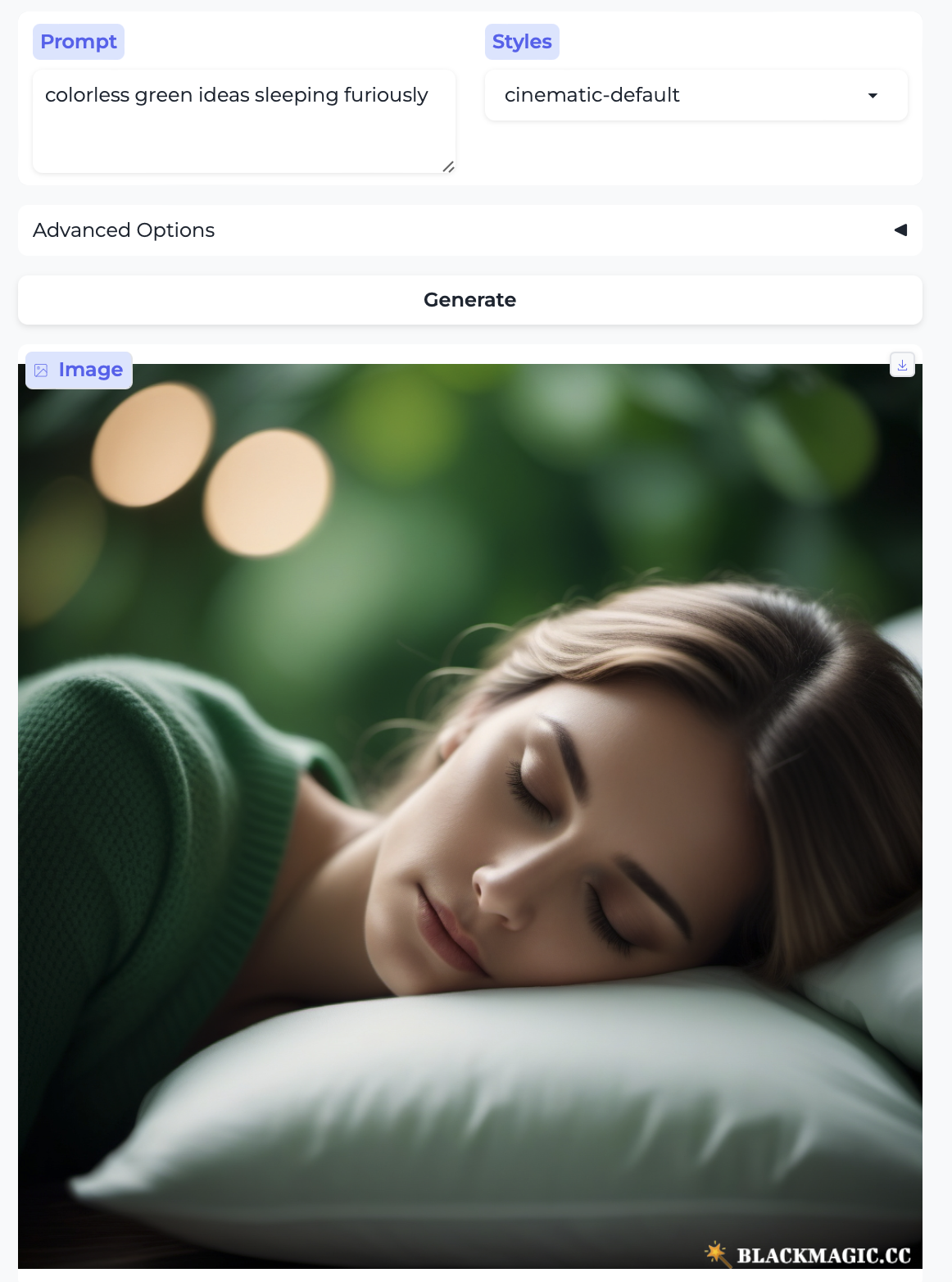
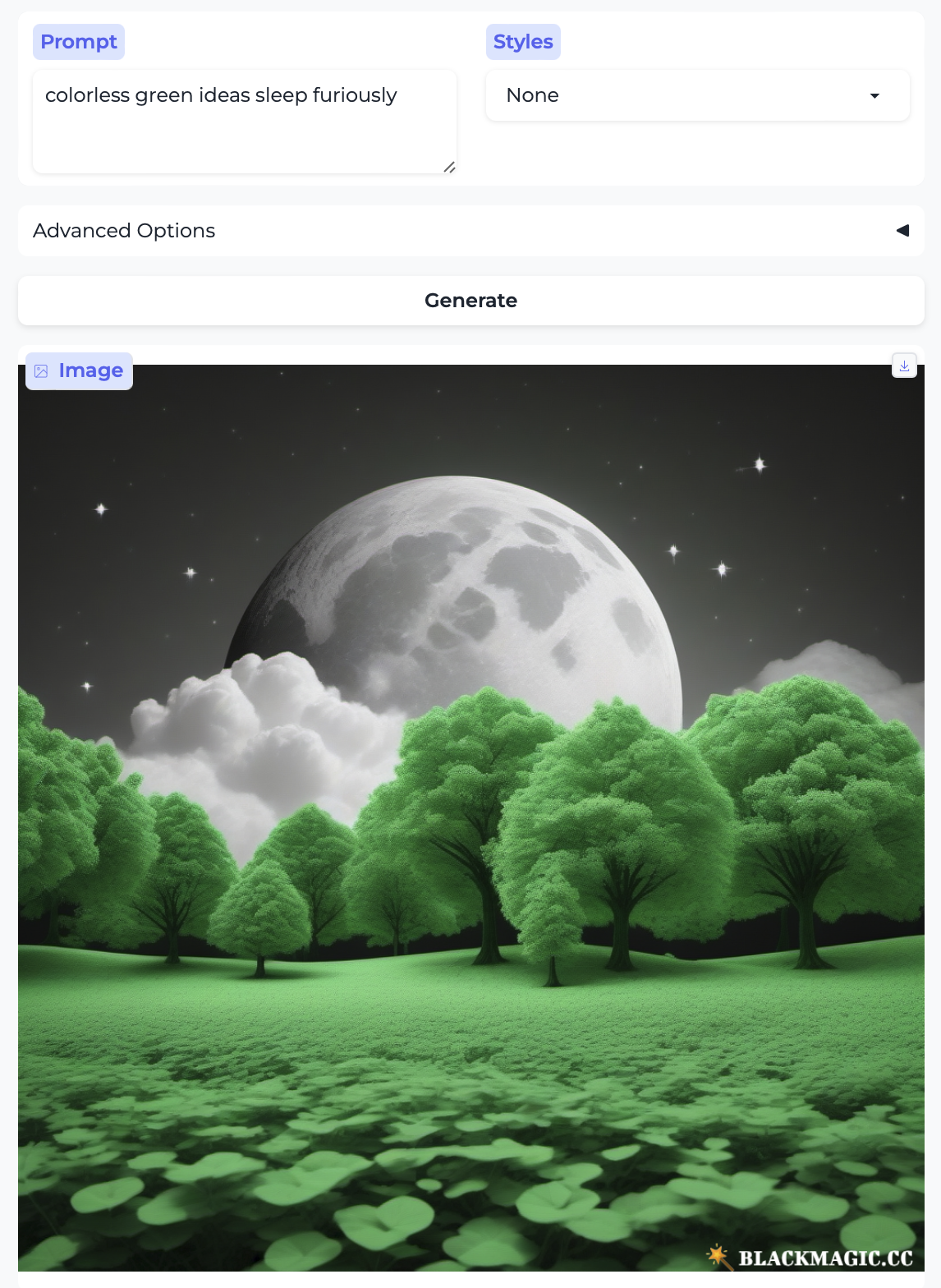
I’d be remiss if I didn’t try out Chomsky’s famous “colorless green ideas sleep furiously” — an example originally presented in order to demonstrate that the role of syntax is separate from that of semantics: we are able to assign a structure to this sentence and we know that it is well-formed, just as we also know that it is meaningless because of the particular lexical items that have been combined here. The model has no trouble producing an image – but it only grabs onto the most basic concepts: “green” and “sleep”. (Bonus: a pretty white woman no one asked for!)
I also tried two complete gibberish phrases – random keyboard smashes lead to pretty random results:


Non-English
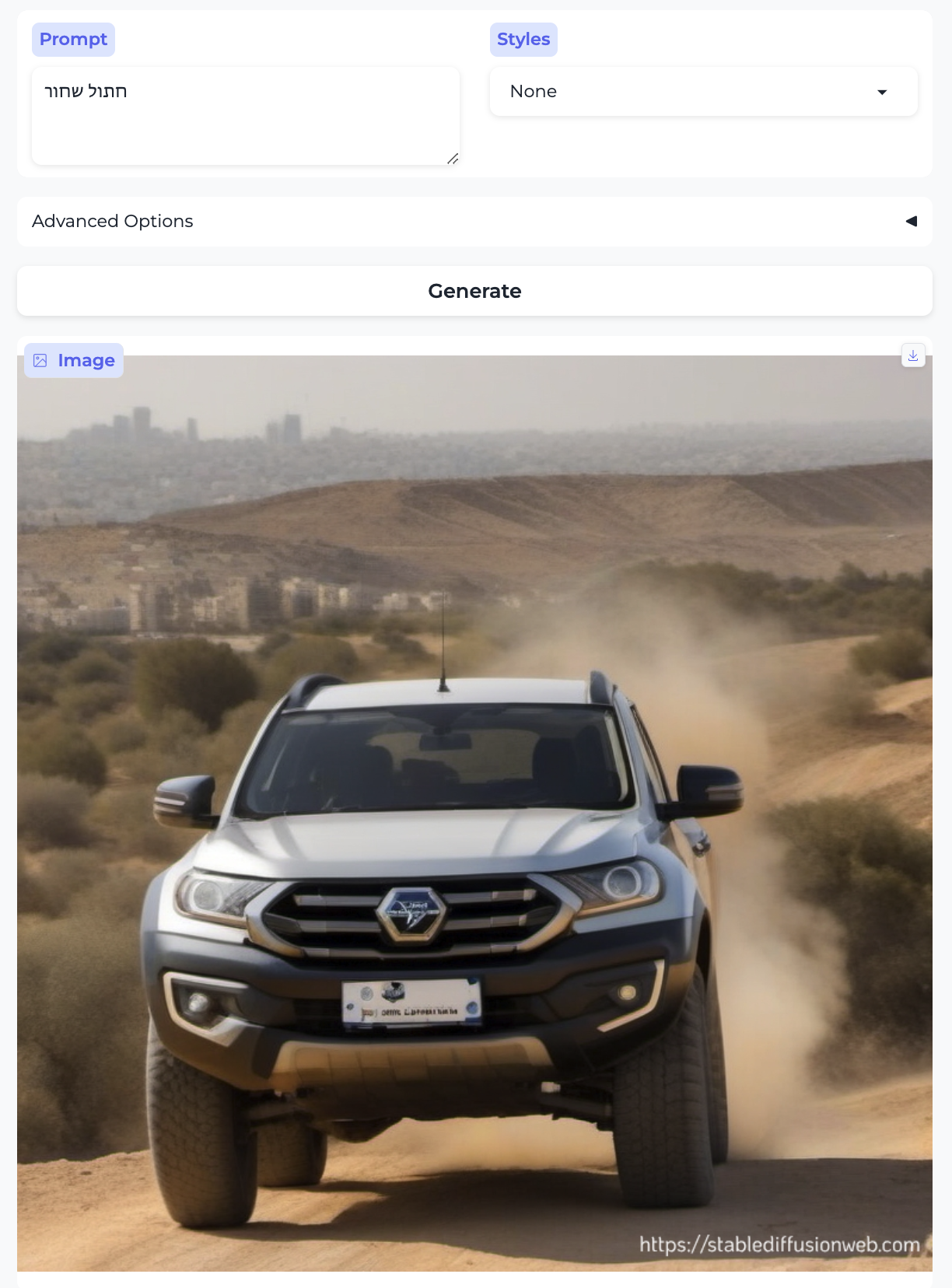
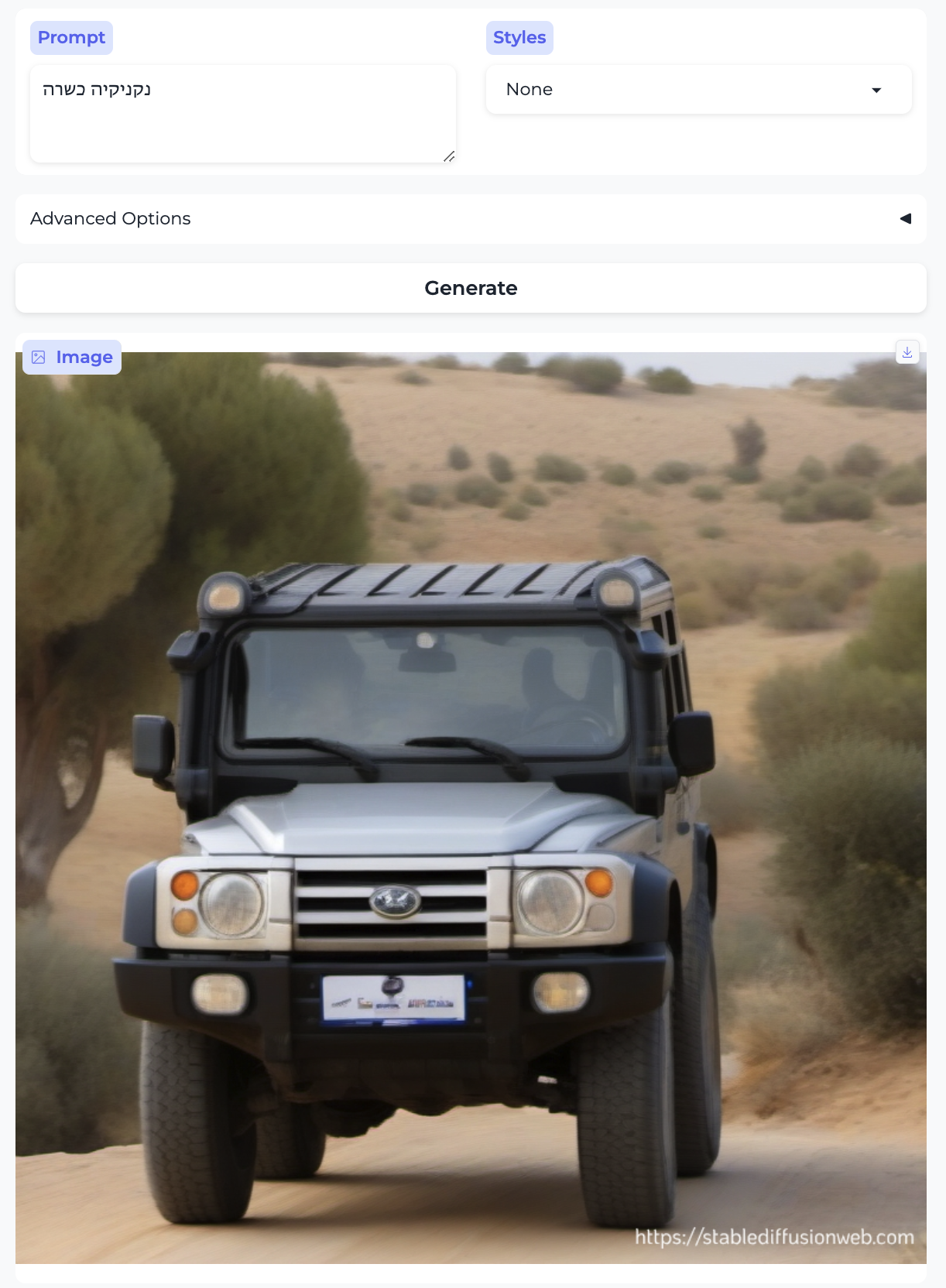
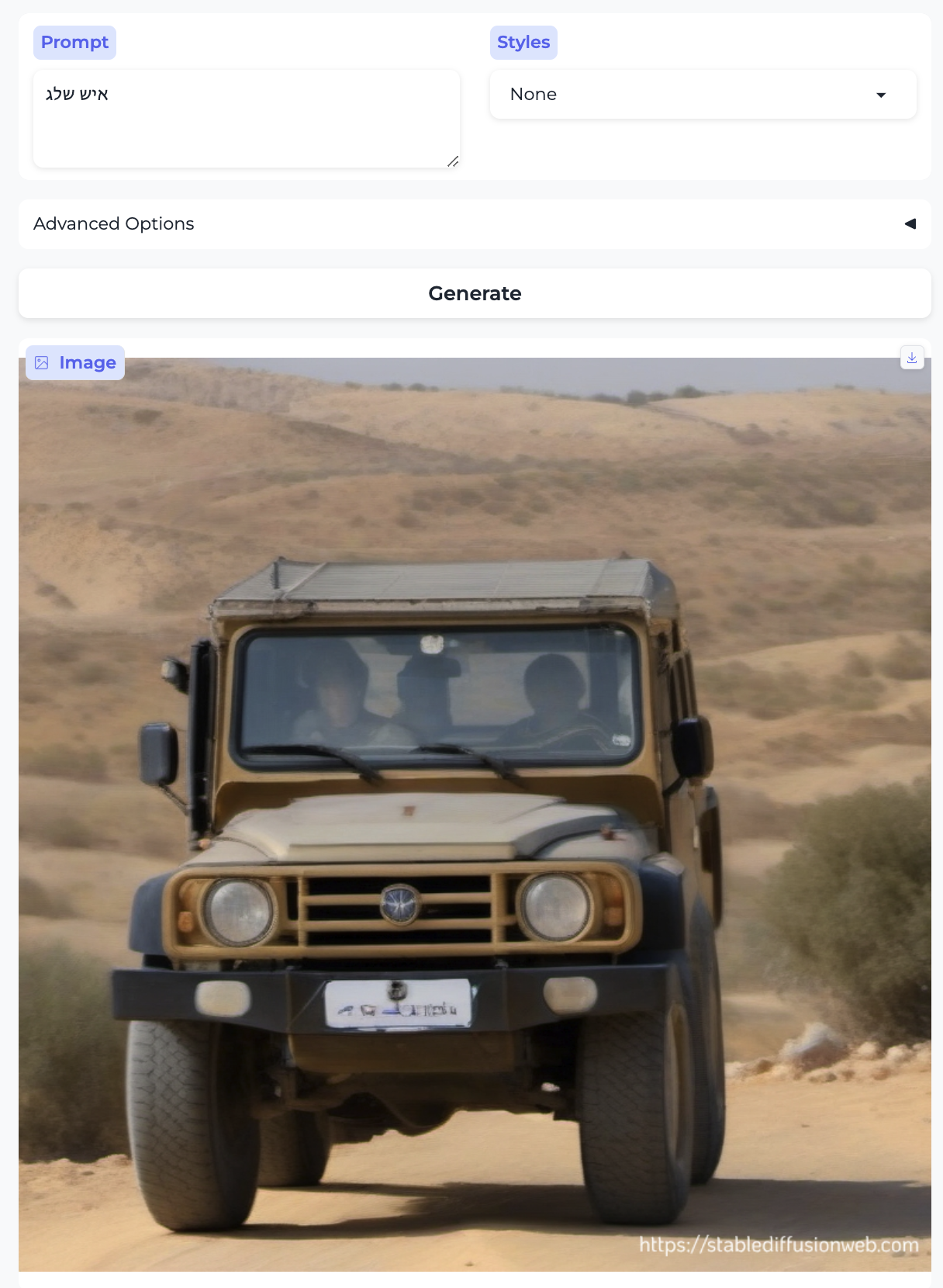
There is no particular reason to think the models are trained on (significant amounts of) non-English data. Here are the results for the Hebrew phrases: “black cat”, “kosher sausage”, “love”, and “snowman”, respectively, which strongly suggest that our suspicion is correct.

And here, on a different day and model seeding, is “pepper”:

(Just to state the obvious, there is no interpretation of “pepper” in Hebrew that means ‘pretty woman’.)
In class, students tried some examples in Thai, Mandarin Chinese, and French. The model did reasonably well on French (I guess there’s more training data for it), but was seemingly random otherwise. This is perhaps not a surprising finding, but there you have it.
Garden path sentences
Another famous grammatical phenomenon is that of garden path sentences. These sentences are interesting because readers are initially tempted to assign one parse to the sentence, but at some point they realize that this parse can’t be right, and are forced to go back and readjust their assumptions. This reanalysis is usually accompanied by a strong sense of confusion and having to go back to re-read the sentence, which can be quite striking.
First, here is a classic garden path sentence: “the horse raced past the barn fell”. It is tempting to initially assume “the horse” is the subject of this sentence and “raced past the barn” is the verb phrase, but upon encountering “fell” we are forced to reanalyze the sentence: “raced past the barn” is a relative clause modifying “horse”, so that the phrase “the horse raced past the barn” is the (complex) subject, and “fell” is the verb phrase.
The model, it seems, isn’t really concerned with all this minutiae. It gives us a galloping horse with a barn in the background, and simply doesn’t illustrate the crucial “falling” part of the sentence.


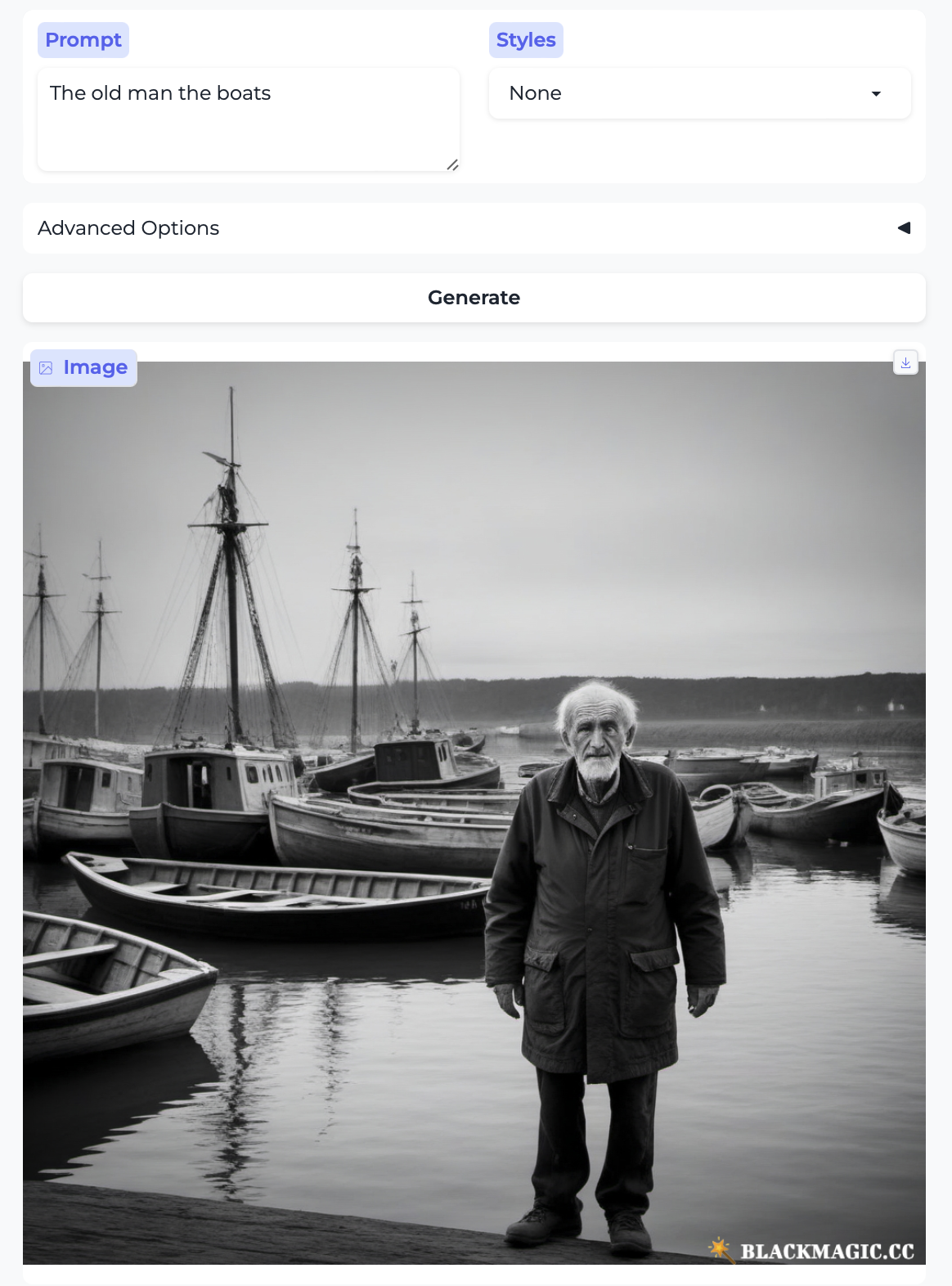
Here is another famous garden path sentence: “the old man the boats”. In this sentence, although we are initially tempted to parse “the old man” as the subject of the sentence, in fact “man” is the verb and its subject is “the old”. The model just gives us an old man and some boats, parsing both as nouns and not minding the syntax at all.
First inklings of bias
I tried two other garden path sentences, which will begin to illustrate just how shallow the model’s parsing abilities are. Discussing bias will be the focus of part 2 of this post, so here I’ll just show a few examples and not comment on them too extensively.
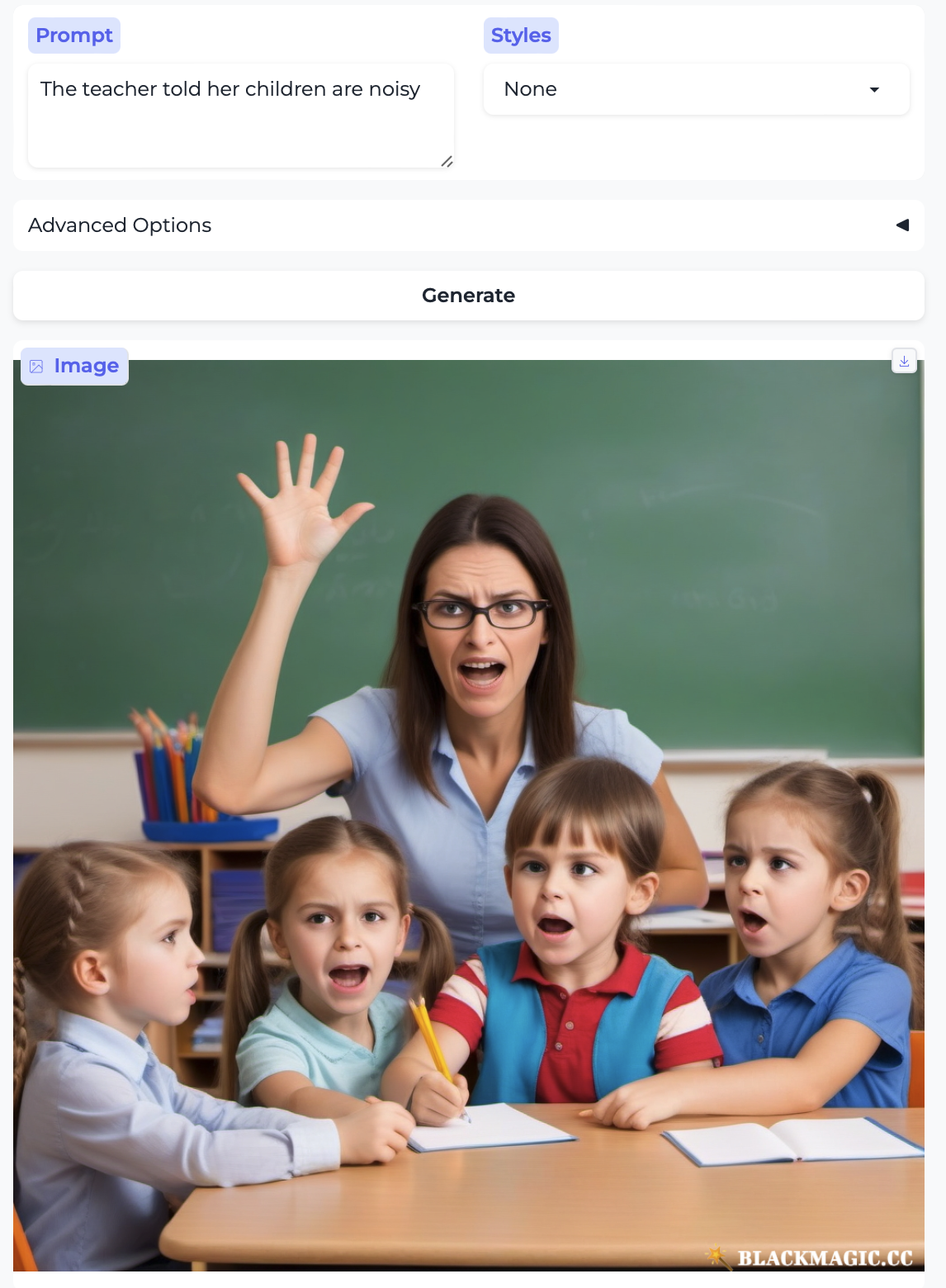
First, here is “The teacher told her children are noisy”. Similarly to the example above, here we’re initially tempted to parse “her children” as the first object of “told”, but we are quickly forced to reanalyze the sentence so that “her” is the first object of “told” and “children are noisy” is the second object of the verb. The model only seems to pick up “teacher”, “children”, and “noisy”. “Noisy” is illustrated by everyone, not just the kids, doing an odd imitation of silent-yelling. Predictably, the kids are doing school-related things. If I replace “teacher” with “doctor”, suddenly the kids are little doctors. Notice also that the teacher is a younger white woman and the doctor is an older white man.

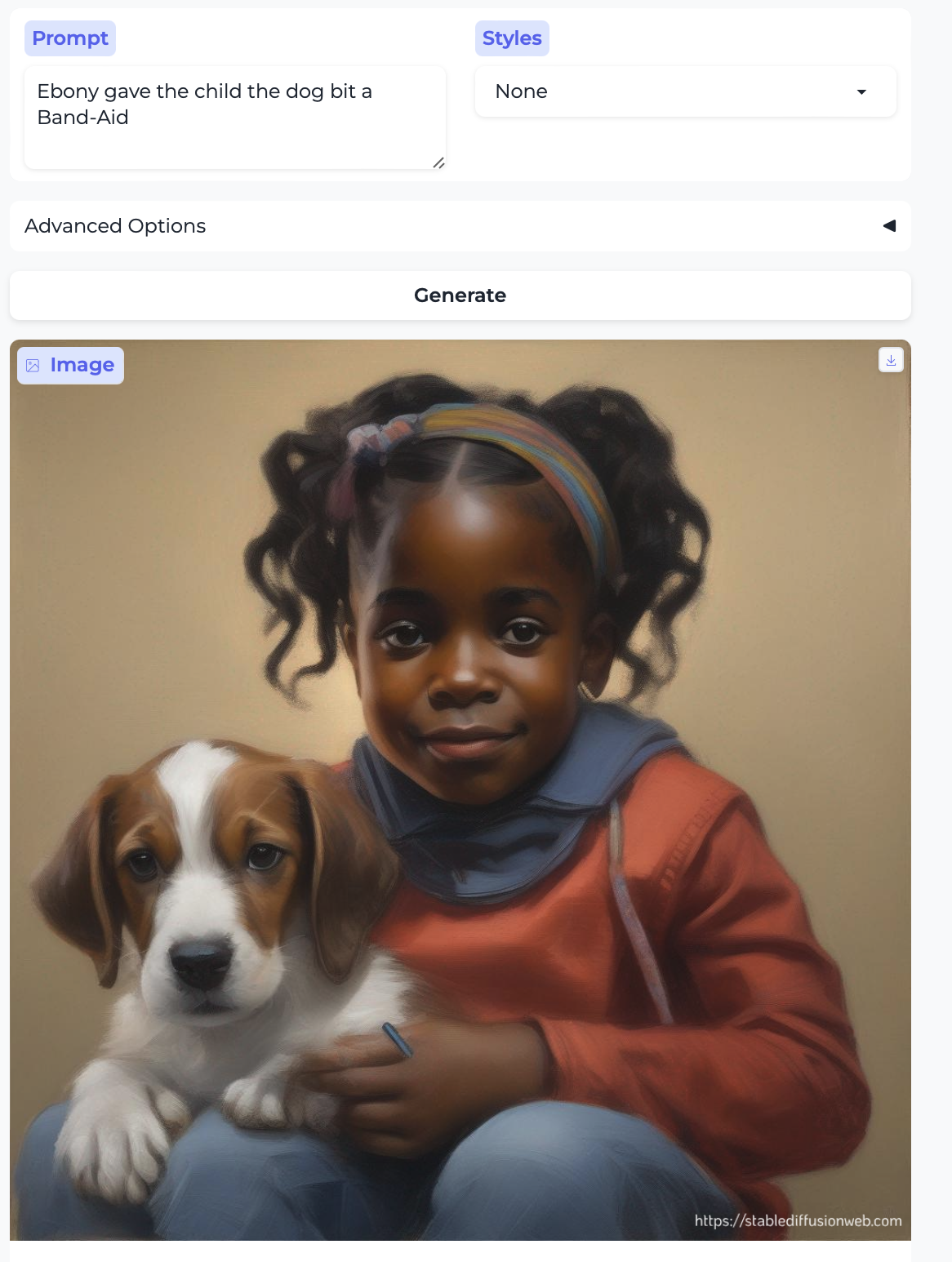
More along these lines, and much more egregiously, is the following series of images, which I started from the prompt “Mary gave the child the dog bit a bandaid”. In case you’re confused, here “the child the dog bit” is the first object of “gave” and “a bandaid” is its second object. The model … took it in a different direction.

So clearly, the name I used as the subject was the single most important thing the model picked out — unsurprising if it’s doing extremely shallow parsing. I’d expect the training data to contain lots of images of the virgin Mary. There’s also a child and a dog here (even though technically the dog is not necessary–the biting happens before the giving of the bandaid), but there is no bandaid that I can see.
That led me to try several more variants (all of the examples below have the shape “[NAME] gave the child the dog bit a bandaid”). Here are:
Sam and Samantha:


DeShaun and Ebony:

Taro and Hanako:


Ahmad and Salma:


Moshe and Hadassah:


… and finally — Hadas (how rude!):

There’s a lot to unpack here:
- stereotypical rendering of individuals associated with the names by race, ethnicity, and gender.
- stereotypical image styles, even though all the images were generated with the “None” style selected.
- non-random distribution of the ages of the human protagonist.
- we always get a single human protagonist, along with a dog, and occasionally the human gives the dog a bandaid. That is obviously not the correct parse of the sentence.
- I can’t decide if there is anything interesting to say about whether the single human protagonist is a child or an adult.
More on these and related issues in part 2 of this post.
Wrapping up part 1
Text-to-image models seem to be shallow and unimaginative. They are, in fact, more inflexible and banal than one might be led to believe given how frequently they are described as useful for being creative etc. in the popular press. They seem to simply regurgitate their training data in deeply navel-gazing ways, and can’t overcome it even for the simplest prompts (‘blue apples’). In addition, there is no indication that any meaningful language processing is taking place, no compositionality to speak of. And there are lots of ethical considerations that come up — I’ll devote part 2 of the post to more of that.
-
The images included in this post were generated between October 30 and November 5, 2023. ↩
-
Most of the images here come from Stable Diffusion XL, since there is no limit on the number of images it will let one generate. I tried some of the same prompts with Dall-E but soon ran out of free tokens. The observations I make here seem to apply to both models equally, but caveats apply. ↩
-
Throughout, I am showing you the first (or sometimes, first and second) images I generated for each prompt. I am not cherry-picking — I generated far too many images and it took far too long to try to generate more than just the one per prompt (two, sometimes, if I was extra curious for some reason). ↩